
Introduction
We have a platform from which we offer hands-on labs for upskilling and learning needs. This SaaS solution from Nuvepro has existed for more than 5 years now and has been serving labs well. Recently we started seeing some strange behaviors with the lab states. A lab state can be Started, Stopped, Created, Deleted, etc.
The high-level architecture looks something like the one below.
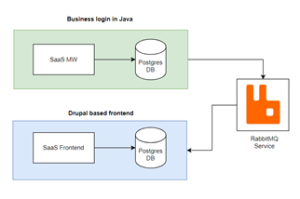
On a particular day, the support team started seeing a bombardment of tickets with multiple issues with lab creation and many other operations like Start, Stop, etc. As we started debugging the root cause, it took us to a hidden world.
Problem – 1
We are using RabbitMQ for the messaging and updating of lab states across product lines. There is a message listener which reads the lab status changes and updates them in the database. Recently we had done a refinement to improve the RabbitMQ message processing by adding more listeners to read and process messages faster. The product is under load balancer, but there was only one listener. This arrangement was changed to have listeners for each node when it comes up.
After some investigations, we realized that multiple listeners could mess up the lab state since the sequence is important. For example: If a user does Start of a lab and a Stop immediately thereafter, as we have multiple listeners processing data, the Stop state change might get updated in the database first and then the Start state. This makes the lab state incorrect.
Solution
We removed listeners running in each node and reverted it to have a single instance that processes lab state change messages.
Problem – 2
The above corrective action handled the issue of mismatch of lab state, however, we started observing slowness in the update of lab status when the load is high (say 300+ concurrent labs). This issue was getting worse over a period and the engineering team was handed over the task of identifying the root cause and fixing it as it started affecting all our customers.
We started suspecting the RabbitMQ listener as the publishing of events seems to be happening correctly from the middleware platform. When we reviewed the message listener code at the frontend, the logic was straightforward, it just receives the message and checks for the availability of the lab, and then updates the status.
The next step was to see how long the query takes to update the database with the latest status. We could see that it was taking more than 1 minute to update the DB. This was verified manually from the SQL CLI and the result was the same.
Found the root cause
The table for the labs was not indexed in the frontend platform hence when the data became huge the query was taking a long time. This was blocking the lab states from getting updated on time. Adding an index to the table resolved it and all the lab status started getting updated correctly.
The above event was an eye-opener towards scalability issues and when we started growing rapidly, unexpected new issues started cropping up.
Watch this space for more….